
FairPrune Achieving Fairness Through Pruning for Dermatological Disease Diagnosis
FairPrune: Achieving Fairness Through Pruning for Dermatological Disease Diagnosis 通过修剪皮肤病诊断实现公平
在修剪过程中,对一个人口统计群体重要的参数可能对另一个人口群体不重要。通过控制参数进行剪枝,我们可以减少特权组和非特权组之间的精度差异,以提高公平性,同时保持它们的整体精度尽可能高。
- 什么是fairness?
作者提出,基于深度学习的医学图像分类模型可能会偏向某些人口统计属性,如种族、性别和年龄。现有的偏差缓解方法主要侧重于学习去偏模型,这不一定能保证所有敏感信息都可以被删除,并且通常会在特权和非特权组上带来相当大的准确性下降。为了解决这个问题,我们提出了一种Fairprune方法,通过剪枝来实现公平。剪枝先前用于减少模型大小以进行有效推理。本文表明剪枝也可以成为实现公平的有力工具。本文发现在剪枝过程中,模型中的每个参数对不同组的准确率具有不同的重要性。通过基于这种重要性差异对参数进行剪枝可以减少特权组和非特权组 ( the privileged group and the unprivileged group) 之间的准确度差异,以提高公平性,而不会出现较大的准确度下降。
Question为什么不一定能保证所有敏感信息都可以被删除?
(Existing bias mitigation methods primarily focus on learning debiased models, which may not necessarily guarantee all sensitive information can be removed and usually comes with considerable accuracy degradation on both privileged and unprivileged groups.)
作者总结了之前的一些缓解偏差的方法:
-
在编码器或分类器的尾部添加对抗性网络来预测受保护属性并形成极小极大博弈:最大化网络预测类别的能力,同时最小化对抗性网络预测受保护属性的能力。 (即使目标受保护属性已经被移除,其他特征的组合仍然可能是这个受保护属性的代理;强制模型忽略受保护的属性相关特征会丢失信息,从而损害其分类准确性)
-
通过解释实现公平:细粒度的特征级注释作为领域知识来训练模型,使其仅关注原始输入中与偏差无关的特征。 (也删除了一些重要信息)
因而,本文提出一种方法,计算每个人口统计组的所有参数的显着性(二阶导数),然后将其用于修剪显示这两个组的重要差异很大的参数以减轻偏差,还可做 trade-off between fairness improvement and accuracy drop,还可以减少网络规模以实现高效部署。
作者先证明了显着性反映剪枝后的准确率下降。
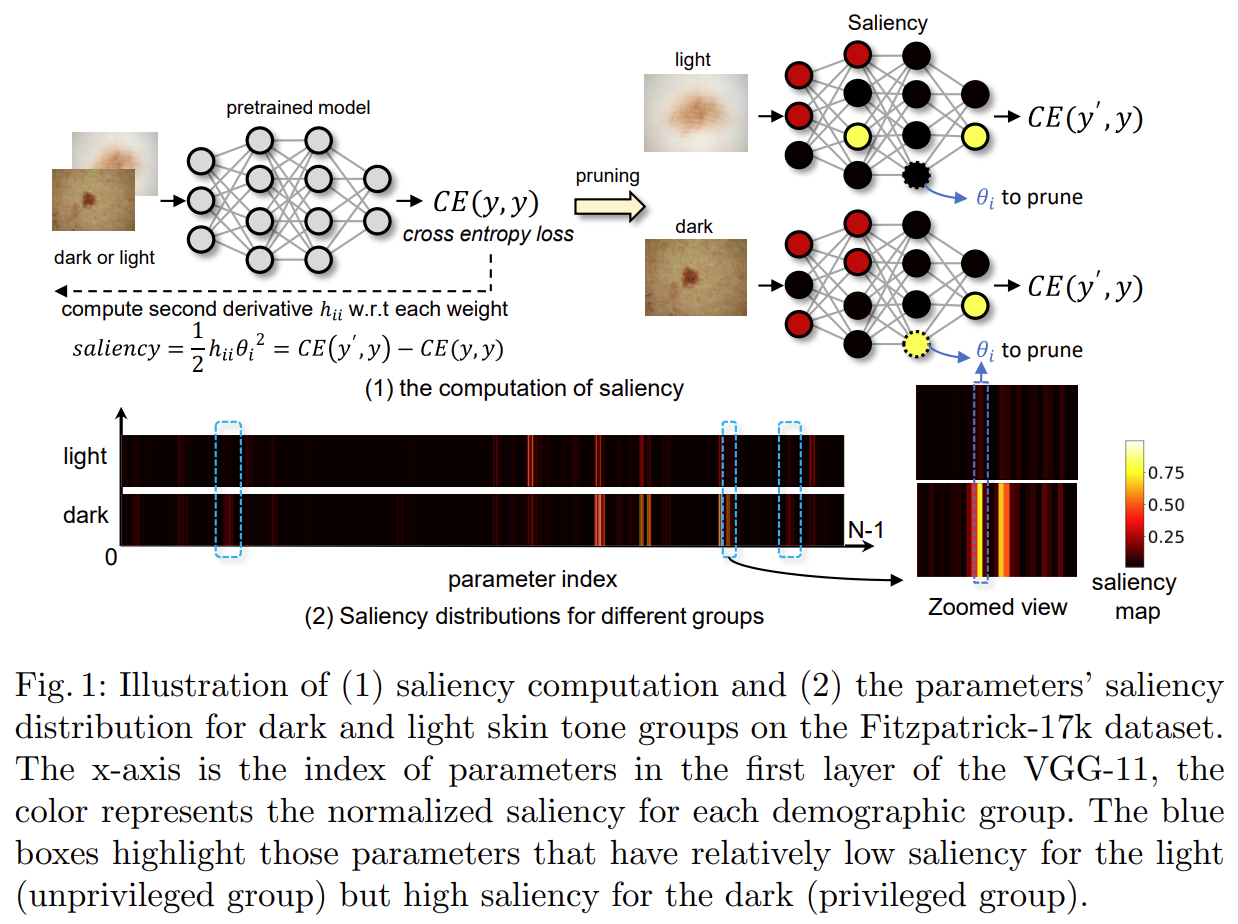
上图显示了一个通过 vanilla 训练预训练的皮肤病诊断模型,该模型偏向于浅肤色患者,即非特权组。这个坐标系代表VGG-11 第一层中参数在暗组和亮组中的显着性分布。 x 轴代表参数索引,其中一个坐标显示亮组和暗组的相同参数。颜色表示两组的归一化显着性。可以看出,这两组的显着性分布存在差异。所以如果能把这样的差异性参数去掉的话,是不是就会让模型的评判更加公平呢?
我个人的理解就是,上下两排差异大的就是要剪掉的参数。就像是评委打分,去掉一个最高分去掉一个最低分这种感觉。
如何识别这样的参数呢?本文提出了一种公平感知显着性计算方法来识别对非特权组不重要但对特权组重要的参数。
本文只关注两类的问题,是被歧视的样本(bias-conflict),是bias-aligned样本。上述公式即是想让剪枝参数后的组的error changes () 更小,让的组error changes ()更大,(就是让被歧视的组变化不大–>保证原有基础结果,让受特权的组变化大–>让他们分数低点,尽量公平)。
Question
为什么是在用泰勒展开,不是在其他值时展开?
其中是对的导数,因为我们假设预训练模型已经收敛,目标函数达到局部最优。是二阶导数Hessian矩阵的第行列的元素。近似假设修剪几个参数引起的ΔE是单独修剪每个参数引起的ΔE之和,因此忽略第三项。
所以我们刚才提出的最小最大优化问题可以转换成:
其中
其中是用来平衡0和1类的tradeoff参数,是模型的参数,可以视作常量,是实现公平性目标的参数的显著性,较小的值表示我们修剪它可以有更大的收益,因为较小的有助于最小化目标函数,是组的hessian元素,这是把每个组的信息输入剪枝过程以实现公平的重要元素。
本文中FairPrune通过以下迭代步骤修建预训练模型:
-
分别从非特权组和特权组采样mini-batch
-
对于每个,计算每个参数的二阶导数,并计算出参数的显著性。
-
在几个mini-batch之后,对每个参数在mini-batch上的显著性做平均,删除显著性最小的。
-
重复步骤1-3,直到达到目标的公平性指标。
评估公平性的指标:
多类的Eopp (equalized opportunity) 和 Eodd (equalized Odds)
数据集:
Fitzpatrick-17k, ISIC 2019 Challenge
