
Shortcut Learning in Deep Neural Networks
Shortcut Learning – 捷径学习
What is a shortcut?
shortcuts are decision rules that perform well on i.i.d. test data but fail on o.o.d. tests, revealing a mismatch between intended and learned solution.
本文主要分享的是实验室中的深度学习应用到现实中不适配的问题。
1. Introduction
深度学习在对我们的生产生活起到很大帮助的同时,人们必须意识到一个问题,如果想将其应用到自动驾驶、简历评估、癌症筛查(共同特征:不恰当的结果会对现实影响很大)等领域,我们必须搞清楚深度学习是怎样起作用的,什么时候深度学习不起作用,为什么会这样?
作者举出了一些深度学习不起作用的例子,比如图像识别识别一头羊,但是神经网络却学会用背景识别羊而非羊本身的特征(羊一般都和草一起出现),识别茶壶的时候看到茶壶花纹出现就认为是茶壶,看到肺炎医院的token出现就把这张图片识别为有肺炎等等,见图1。以上这些神经网络“投机取巧”式学习使用到的特征被我们称之为Shortcut。

2. Shortcut learning in biological neural networks
作者在第二节中以小鼠走迷宫(discriminated the colours by the odour of the colour paint used on the walls of the maze instead of using vision systems) 、死记硬背学习法(learned the whole book chapter by rote Vs. immersing oneself in the whole history)这两个例子从生物的神经网络层面介绍了Shortcut learning。
3. Shortcut learning in Education: surface learning
在第三节中,作者提出了一个toy model来证明神经网络在学习时的的确确会存在shortcut learning的模式。
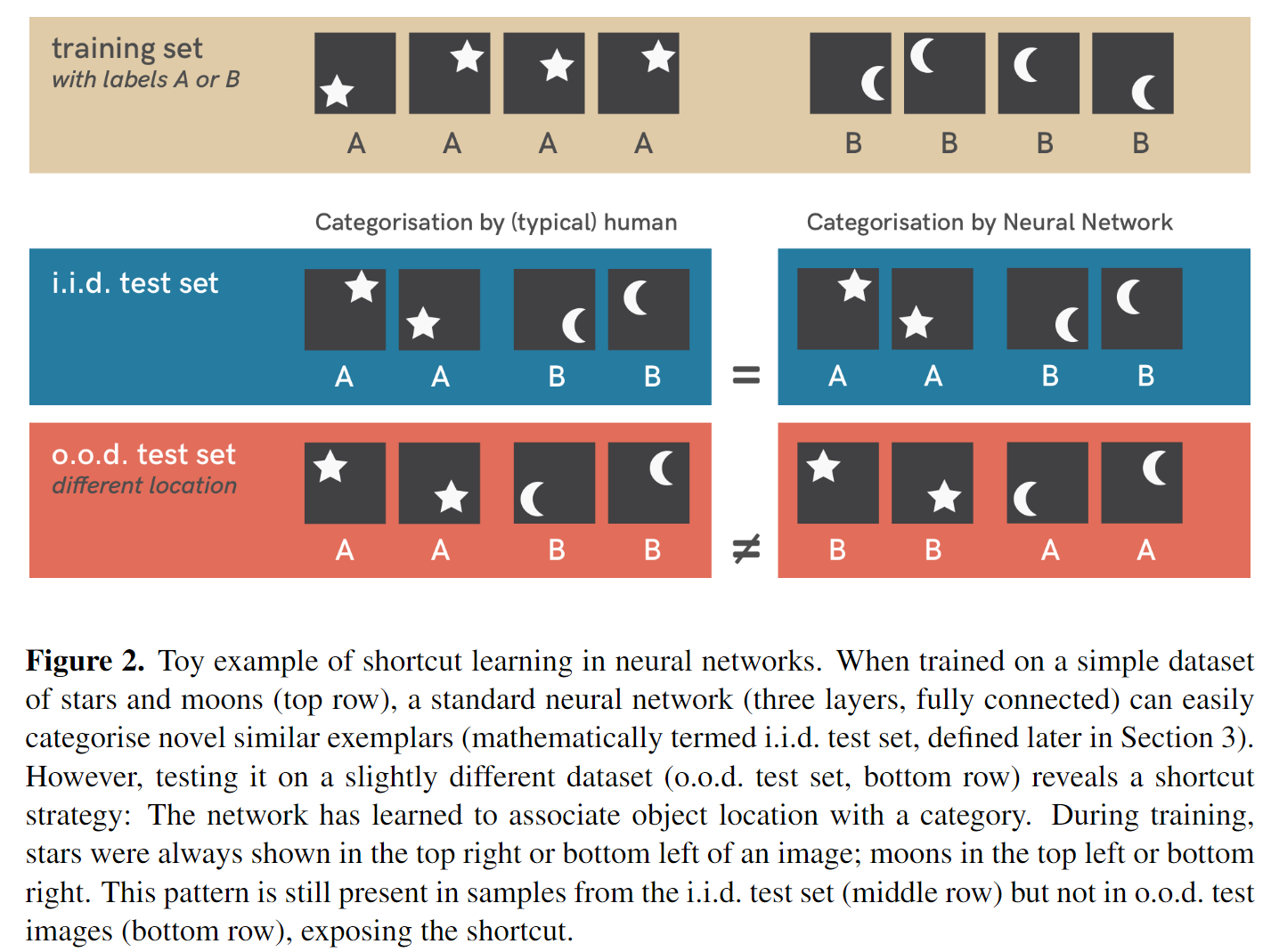
见上图,人类识别月亮和星星是通过形状来进行的,这也是人类希望神经网络这样做,然而神经网络却根据图像出现的位置进行识别,这就是一种Shortcut Learning。作者将神经网络在训练过程中可能用到的方法进行归类:
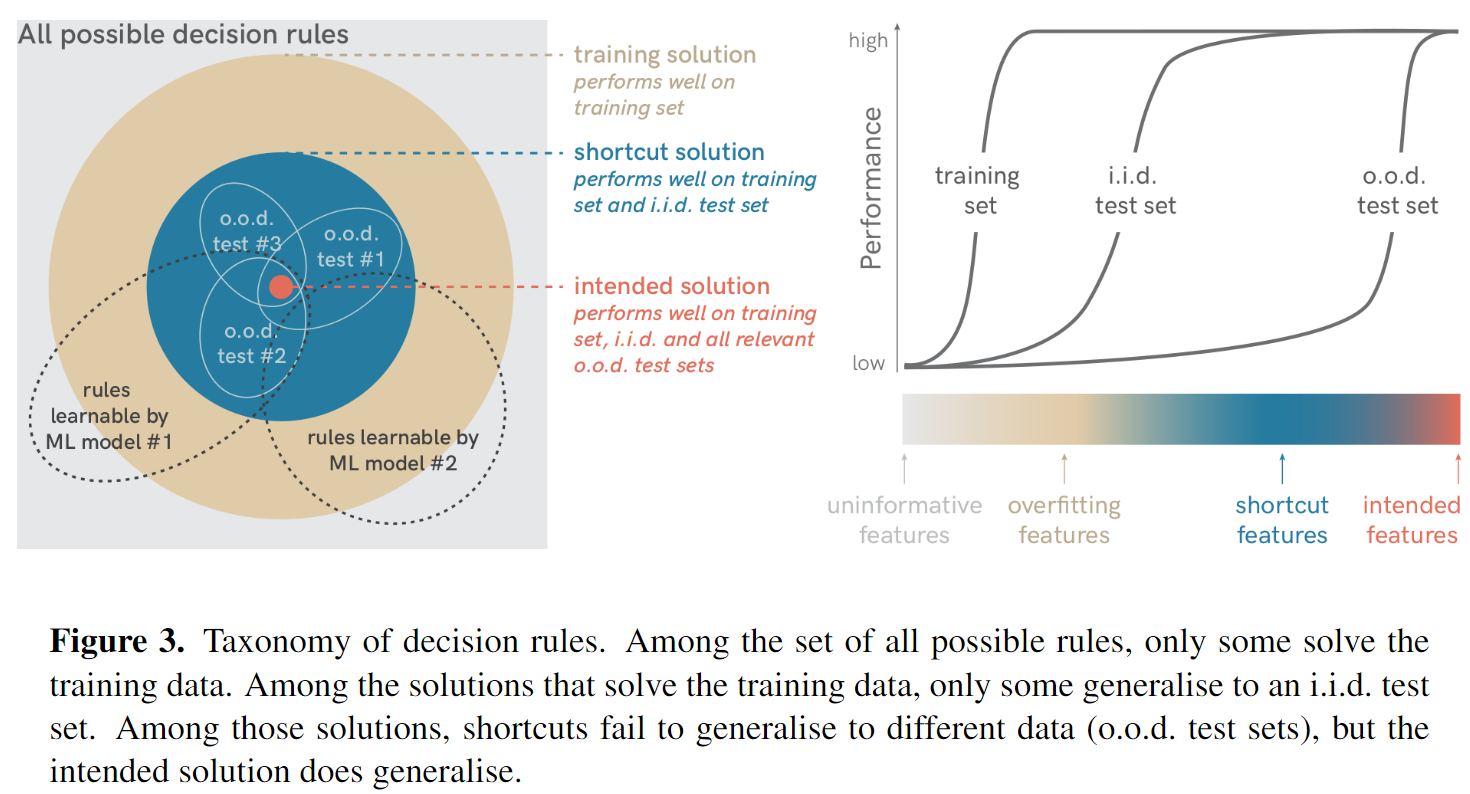
3.1 all possible decision rules, including non-solutions
这个意思是通过检测图片中是否有白色像素,如果有的话则认为是star,很明显这种solution很难达到令人满意的效果。
3.2 training solutions, including overfitting solutions
这个意思是模型完全使用训练集中的特征(假设测试集iid),从而使预测结果过拟合,并没有给出实际例子。
3.3 i.i.d. test solutions, including shortcuts
这个意思是我们训练的模型很完美的将训练集和i.i.d的测试集都拟合了,然而简单想想模型的拟合方式也可以有:判断形状、计算白色像素的数量、看图形出现的位置等解决办法。因为测试集中都是独立同分布的数据,我们没法验证这个问题。而后用ood(out-of-distribution)的数据集测试时我们发现模型是学会了看图形出现的位置判断是moon还是star,这就是一种shortcut。
3.4 intended solution
通过上面三种类型我们知道了一个好的模型需要既能在iid测试集上效果好也能解决ood数据集,这种模型学到的solution就是我们想要的(intended solution)。
以上几种solution可以用下图进行分类。
4. Shortcuts: where do they come from?
在第四节中,作者讨论了shortcuts的来源,分为以下几个方面:
4.1 Dataset: shortcut opportunities
主要是讲Dataset Bias,即要识别的物体的背景会干扰预测,如果一头奶牛出现在水里,神经网络很难将其识别为奶牛(相比于在草地里而言)。如果仅仅将数据集放大几个量级,dataset bias的问题不可能消失。

4.2 Decision rule: shortcuts from discriminative learning
如果把图片中猫的皮肤换成大象皮肤的纹理,神经网络很有可能会把猫识别成大象,因为神经网络识别时很依赖texture,很有可能忽略了global object shape。因而模型在做决定时最好不要仅仅依赖一种特征,不然很容易造成shortcuts,然而和人类判断一模一样也不一定是好的,比如疾病检测时人们希望机器可以表现得优于人类。判别式学习(discriminative learning)可能会导致某些决策规则依赖于单个预测像素,忽略了其他的证据;Standard DNN不会对中间图像表示加任何可解释性的要求(换句话说,学出来的representation无法解释含义,就单纯直接用了),所以会导致模型严重偏向于提取简单的特征,这样会导致模型泛化力下降。

4.3 Generalisation: how shortcuts can be revealed
泛化与捷径学习:泛化和鲁棒性可以认为是shortcut learning的另一面,shortcut learning可能是泛化到了一个不好的层面。同时,DNN和人类对物体变化的敏感程度也不同,比如旋转、噪声于人和抽象与DNN,见图4。泛化失败并不是学习失败也不是不能泛化,而是没有在预期方向上泛化。使用特定的一组特征会导致对其他特征不敏感。只有在分布变化后所选特征仍然存在时,模型才会泛化到o.o.d数据集上。
5. Shortcut learning across deep learning
作者在第五节介绍了一些深度学习中具体的领域中的Shortcut Learning。
5.1 Computer Vision:
图像的平移、旋转、加噪声、模糊、换背景、换纹理都有可能造成DNN识别图像错误。对于CV领域的Shortcuts来说,domain transfer(跨数据集间的模型迁移)就是一个challenging problem,因为模型经常要用到domain-specfic shortcut features。此外,adversarial examples也可以认为是一种shortcut learning的结果,因为人眼不可见的改变导致DNN的预测结果变了。
5.2 Natural Language Processing:
BERT、GPT-2等模型都需要有一些cue words才能用,比如以下例子:
It learned that within a dataset of natural language arguments, detecting the presence of “not” was sufficient to perform above chance in finding the correct line of argumentation.
在验证正确方法时,简单的通过找“不”这个字来进行,这样完全不需要理解文章的内容就可以做到了。并且在NLP中也会有一些dataset bias比如annotation artefacts的问题(Question:这是什么问题?),此外,feature combination大多都含有比如word length等这种shortcut features。这也是导致NLP任务很难泛化的原因之一。
5.3 Reinforcement Learning
tbd
5.4 Fairness & algorithmic decision-making
Tasked to predict strong candidates on the basis of their resumes, a hiring tool developed by Amazon was found to be biased towards preferring men. The model, trained on previous human decisions, found gender to be such a strong predictor that even removing applicant names would not help: The model always found a way around, for instance by inferring gender from all-woman college names.
一些公平算法的设计中总会遇到类似的shortcut:当模型发现了一种决定预测的特征时,即使只是所有特征的一部分,模型也会倾向于根据这种特征进行预测。这被称之为bias amplification。还有比如因为关注数据集中的多数群体从而包容少数群体的高错误率(决定让绝大多数人满意,但是忽略了少数群体),会放大现有的社会差异,称之为disparity amplification,因为模型中的sequential feedback loops会放大模型对多数群体的依赖。
6. Diagnosing and understanding shortcut learning
在本节中作者提出了三种shortcut learning的分析与解决办法。
6.1 Interpreting results carefully
6.1.1 Distinguishing datasets and underlying abilities
机器学习中most popular benchmarks仍然是i.i.d测试集,以ImageNet为例,它衡量模型“对象识别”的能力,但DNN主要是通过计算纹理来达成这一结果的,或者对于自然语言推理任务而言,一些语言模型通过检索关键词达到投机取巧的效果。总之,只有在数据集能很好的代表人们所需要的能力时它才是合适的数据集。
6.1.2 Morgan’s Canon for machine learning
以前文提到的小老鼠走迷宫为例,小老鼠通过闻迷宫上不同位置涂的油漆的味道来辨别方向,而不是人们所希望的通过视觉辨别方向。动物(Neural Network)通常会不使用人们实际感兴趣的潜在能力,而是通过以意想不到的方式解决实验范式(Dataset)来欺骗实验者。因而我们将心理学家Morgan所提出的一条原则应用到机器学习中:永远不要将可以通过shortcut learning充分解释的能力归功于高级能力。
6.1.3 Testing (surprisingly) strong baselines
用一些比较好的baseline来测试他们是否取得超出预期的效果,即使他们没有使用预期的特征(用了一些shortcuts),比如使用KNN估计地理位置,使用局部特征进行对象识别,基于单个提示词的推理等等。
6.2 Detecting shortcuts: towards o.o.d. generalisation tests
6.2.1 Making o.o.d. generalisation tests a standard practice
大部分都是通过i.i.d测试集来评估模型指标,我们使用o.o.d测试集来评估模型可以更好的得出预测结果。比如,在死记硬背学习法的例子中,我们把选择题换成论述题,就会很大程度减少这种问题。本质上讲就是make test set more challenging 。
6.2.2 Designing good o.o.d. tests
如何定义一个好的o.o.d test?
-
需要有clear distribution shift,不管是否能被人类区分。
-
需要有一个明确的intended solution,所以在普通图像上训练,在白噪音图像中测试是一个o.o.d测试,但却没有intended solution。
-
一个好的o.o.d test应该是让目前主流的模型很挣扎的。
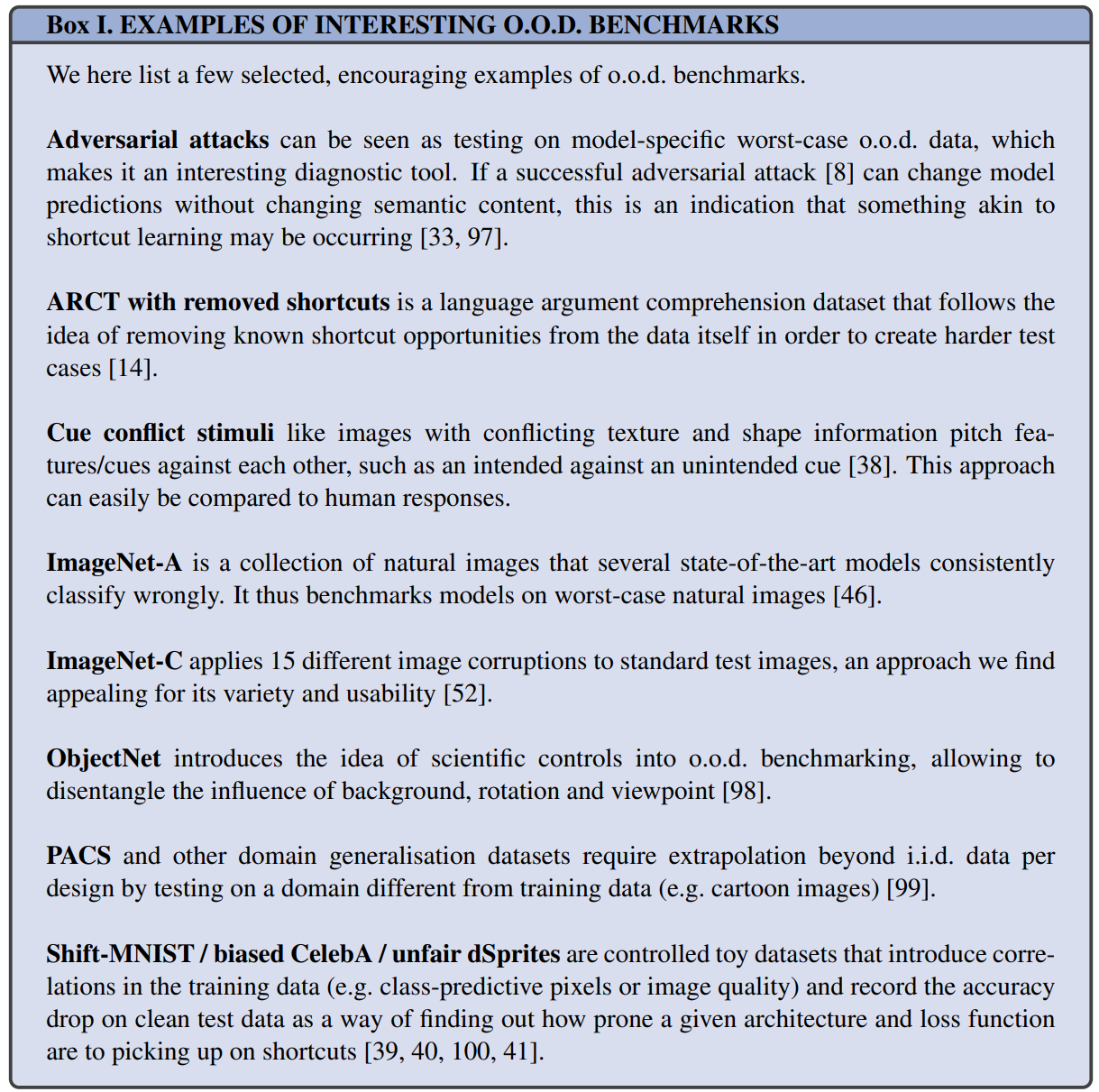
o.o.d test应该是和他们想评估的模型一起发展的,作者也提供了一些encouraging examples,见Box 1。
6.3 Shortcuts: why are they learned?
6.3.1 The “Principle of Least Effort”
在语言学中,有一种现象被称为“最少努力原则”,就是沟通者会尽量减少交流中所涉及的努力,比如用plane代替airplane等等,总之就是不要多做,够了就行。
6.3.2 Understanding the influence of inductive biases
解决方案是否易于让机器学习不仅取决于数据,还取决于机器学习算法的四个部分:architecture, training data, loss function, and optimization. shortcut learning和inductive bias(归纳偏差)的关系可以在Box 2中看到。

6.4 Beyond shortcut learning
在本节中作者提出了一些可以避免shortcut learning的办法
6.4.1 Domain-specific prior knowledge
-
通过设计不鼓励学到shortcut features的结构和数据增强策略来避免对unintended cues的依赖。
-
如果对象的方位与他的类别无关,可以使用数据增强或者hard-coded rotation invariance(简单来说应该就是旋转)
-
Extreme data-augmentation,迄今为止最成功的semi-supervised和self-supervised方法的核心成分
6.4.2 Adversarial examples and robustness
对产生特定输出的输入的最小更改。实现与人类意图一致的预测的反事实解释,使得对抗鲁棒性的最终目标与机器学习中的因果关系研究紧密耦合。但相关研究主要侧重于与模型无关的噪声,如图像损坏等。
6.4.3 Domain adaptation, -generalisation and -randomisation
通常,在训练期间会观察到多个分布,并且模型应该在测试时推广到新的分布。在某些假设下,可以从多个领域和环境中学习intended (even casual) solution。在机器人技术中,域随机化(在训练期间随机设置某些模拟参数)是一种非常成功的学习策略的方法,可以推广到现实世界中的类似情况。(主要针对o.o.d)
6.4.4 Fairness
个体公平旨在以类似方式对待相似的个体,而群体公平旨在对待与其他人群没有区别的子群体。公平与泛化和因果关系密切相关。敏感组成员身份可以被视为一个领域指标:就像机器决策通常不应该受到改变数据领域的影响一样,它们也不应该偏向少数群体。
6.4.5 Meta-learning
学习可以快速适应新条件的表示。
6.4.6 Generative modelling and disentanglement
Research on disentanglement addresses this shortcoming by learning generative models with well-structured latent representations. The goal is to recover the true generating factors of the data distribution from observations by identifying independent causal mechanisms.
7. Conclusion
The road reaches every place, the short cut only one. – James Richardson
