
Summarization for Debiasing Metrics
Beginning 前置知识
Debiasing 的工作是指去除模型可能学到的数据集中的一些偏向,偏向(Shortcuts)是指模型倾向于学到那些比预期特征更容易学会的特征。
Dataset biases would be preferred when they were easier to be learned than the intended features.
- 如何定义数据集是Biased?如何定义一个bias attribute?
Consider a dataset where each input can be represented by a set of (possibly latent) attributes for that describes the input. The goal is to train a predictor that belongs to a set of intended decision rules , consisting of decision rules that correctly predict the target attribute . We say that a dataset is biased, if:
(a) there exists another attribute that is highly correlated to the target attribute (i.e., ),
(b) one can settle an unintended decision rule that correctly classifies . We denote such an attribute by a bias attribute.
举个例子,我们想训练一个模型用于识别出图片中的动物是不是羊,我们选取了很多张正在草地吃草的羊的照片用作正样本,选取在海里游的鱼作为负样本。对于这样一个训练集的输入(input)而言可能存在的特征(attribute)有:羊(前景), 草(背景), … 我们希望模型学到的规则(intended rule)是:看到长成这个形状的就是羊,但是模型也有可能学到的规则(unintended rule)是:背景有草的动物是羊。这样的数据集就称为biased dataset。
- bias-aligned 和 bias-conflict的定义
对于一个 样本(sample) 而言,如果它的target和bias attributes高度相关,我们称之为bias-aligned,反之称之为bias-conflict。
首先我们观察到一个有偏差的数据集并不一定会让模型学习unintended rule;只有当偏差属性比目标属性“更容易”学习时,偏差才会对模型产生负面影响。为了验证这一观点,我们做了如下的实验:
SbP Dataset: For the training set, we first randomly sampled 5,000 pneumonia cases from MIMIC-CXR and 5,000 healthy cases (no findings) from NIH. We then sampled 5, 000 × r% pneumonia cases from NIH and the same amount of healthy cases from MIMIC-CXR. Here, the data source became the dataset bias, and health condition is the target to be learned. We created the validation and the testing sets by equally sampling 200 and 400 images from each group (w/ or w/o pneumonia; from NIH or MIMIC-CXR), respectively. We varied r to be 1, 5, and 10, which led to biased sample ratios of 99%, 95%, and 90%, respectively. Moreover, as overcoming dataset bias could lead to better external validation performance, we included 400 pneumonia cases and 400 healthy cases from Padchest to evaluate the generalization capability of the proposed method. Note that we converted all images to JPEG format to prevent the data format from being another dataset bias.
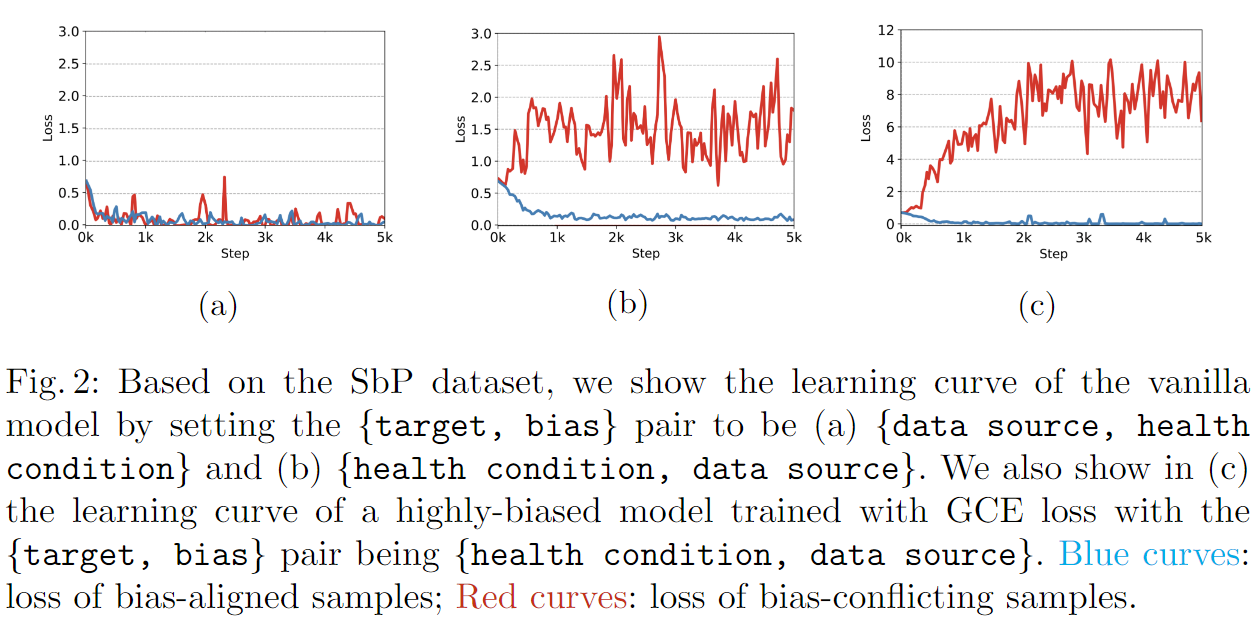
从(a)中可以看出,在我们想区分data source (target)的时候,health condition (bias)对我们的模型并没有影响(因为红蓝两种线都能收敛,证明bias-aligned和bias-conflict对模型没影响);从(b)中可以看出,模型尝试用bias来作为区分training data的依据(因为蓝色的线很快收敛,红色的线不收敛,证明bias-aligned对模型有好的影响);(c)实验是我们加入了GCE Loss之后的结果,我们发现模型对bias更加敏感了。
- GCE Loss 为什么可以让bias更加敏感?
是神经网络中softmax层的输出,是时的概率。在GCE里,q取值范围是,代表了bias的放大系数,当q趋于0时,GCE就近似普通的CE loss。和普通的CE相比,GCE会给那些有更高概率被预测为target的sample更大的gradient,这样就能使模型更注重“易区分”的sample,从而变得bias。
因此大家想到了一些debias的方法。
LfF
Nam等人提出了一种方法,先使用GCE loss训练一个bias的模型A,再关注那些与模型A的preference相反的样本训练得到一个unbias的模型。在训练debias模型的时候使用CE Loss,但是为了更好的关注那些与模型A的preference相反的样本,作者使用了一个reletive difficulty score对CE Loss进行加权:
简单分析一下,bias模型的偏向样本的小,趋于0,unbias样本的大,趋于1。
Question为什么这里不是用GCE,是用CE算score?
模型总体算法如下:

DFA
Lee等人提出了一种方法,同时训练两个网络 (intrinstic)和 (biased),是encode,是linear classifier。(希望使用GCE Loss训练, 使用CE Loss训练),同样计算出每个样本在和两个网络下的reletive difficulty score:
是经过encode层后的特征向量。
作者之后设定了disentanglement过程的objective function:
将和均用这个Loss进行训练。但是是分别做Back-propagation的,就是。
分析一下这个Loss的构成:对于bias-aligned sample,,是GCE Loss;对于bias-conflict sample,
对于bias-conflict sample的是什么?
而后,作者又希望更好的捕捉到intended features,所以又设计了一个交换操作,简单来说,把每个batch中的intrinsic vector和bias vector交换,从原理上来说相当于把前景和背景换一下,只不过是以向量的方式交换,得到交换后的增强向量,而后算出
在交换过后设定Loss为:
并用这个作为新的损失函数进行更新。
Question为什么中的不是
同样的,作者发现并不是一上来就用对两个网络进行更新效果最好,因为前几个迭代过程中没有完全解耦,所以前面用。总体算法如下:

这篇文章写的不太清晰,我也有很多没搞懂的地方,还需要再研究一下。
BiasCon 、BiasBal & SoftCon
Hong等人提出了三种Loss,希望在损失函数层面对debias问题做出贡献。
首先考虑bias label是一类一类的(categorical),并且对于所有的训练样本都是已知的(比如每个训练样本的性别或种族已知)。作者发现biased model倾向于从整个Bias feature space中学习特征并利用这些特征进行预测,因此在相同bias类中的样本在特征空间中彼此接近,因此设计了一个Bias-Contrastive Loss (BiasCon)用来激励模型将具有相同目标类(target class)但具有不同偏置类(bias class)的sample pairs拉近。
BiasCon Loss的构成如下:对于一个容量为的样本集,对其进行随机增强(裁剪、旋转等)使之在一个batch中拥有规模的数据集,BiasCons loss公式如下:
其中是每一个batch的index,是与第个样本配对的正样本(positive samples: same target class but different bias class)集的index,是从中提取的第个样本的归一化特征,是温度超参数。
最终的目标函数是BiasCon损失和CE loss的线性组合。
其中是模型对第类的预测,是原始batch的index集。
在本文的实验中,具有相同目标和偏差类的样本被认为是negative pairs。因此,与CE loss联合训练更有效,因为 it can give signals to incorporate all the same class samples。
Questionit can give signals to incorporate all the same class samples这句话是什么意思?给出signals来合并所有相同的类样本?看不懂。
当高度不平衡时,单个batch可能不包含足够的positive pairs,因为batch中的大多数相同类样本将具有相同的偏差特征。这可能会导致不稳定的优化。为了解决这个问题,对于训练集,我们分别对第i个样本的BiasCon损失的batch进行修改采样频率的采样。我们设计了来对具有低的进行过采样,以便在batch中有更多的positive pairs可用:
大小为的batch之后按来采样。在训练前我们用训练集的标签来提前计算。关于的公式中的最大值是,因而每个训练数据都有机会抽样。
Question是采样频率,它的最大值和训练数据的抽样概率有什么关系?
高度不平衡的抑制了能够正确分类相同偏差标签下的少数数据的特征的学习。因而作者提出了一种bias-balanced regression,该方法使模型向和之间一致相关的数据分布进行偏置。
BiasBal、SoftCon tbd
DivDis
本文使用一个labeled source dataset 和一个unlabeled target dataset来进行实验,假定这两个数据集之间存在subpopulation shift,希望找到一个函数能在目标数据集上表现很好。
两个阶段,Diversify + Disambiguate (DivDis),考虑一个未指定的奶牛-骆驼图像分类任务,其中源数据包括背景为草的奶牛和背景为沙的骆驼的图像。想象两个完全不同的分类器,每个都在源分布中实现了完美的准确性:一个按动物分类,另一个按背景分类。unlabeled target dataset在包含一些在已知标签的情况下可以导致模糊性的例子时最有用,例如,沙漠中的奶牛图像。DivDis先训练一组不同的函数,每一个都可以较好的拟合任务,然后在最小的supervision下选择这个集合中的最佳函数。
Diversify阶段不是让一个多头网络的头部输出彼此不同的预测,而是训练这些头部产生的预测在统计上接近相互独立。因而对于每个头而言先用Cross Entropy作为损失,而后最小化每对预测之间的互信息,并加入一个正则化项防止函数只预测出整个目标集的一个标签。
Disambiguate阶段可以理解为使用指定源和目标数据集以外的信息,比如一旦我们的模型学习了奶牛-骆驼任务的动物分类器和背景分类器,我们就可以通过请求一张沙漠中奶牛的图像的地面真实标签来快速判断哪一个是正确的。作者给出了三种消歧方法。
- 主动查询:根据头部预测之间的总距离对每个目标数据点进行排序,从target dataset中选一小部分最能代表这个数据集的数据(值最大的,我个人理解这个过程相当于比如图像分割任务,对于某张图片三个头做了三次分割,计算出这三个分割之间的距离,也就是说不同的头预测的差距越大证明这个点越能体现出不同head之间的差别),测量N个头相对于选出来的小标记集的accuracy,并选择accuracy最高的头。
对于分类任务,如何计算不同classification的距离?是否需要一些distance metric?accuracy怎么测量?这个选出来的小dataset是unlabelled。
-
随机查询:从target dataset中随机选一小部分数据。
-
消除源数据的歧义:即使两个函数在标签方面接近最优,源数据的其他属性通常也可以区分这两个函数。比如可视化技术可以揭示每个头部的预测是基于图像的哪个区域。这些区域可以与人类观察者的真实预测特征进行比较。这种比较也可以使用现有的bounding-box注释或像素级分割标签(例如那些用于ImageNet和COCO数据集的标签)以自动的方式执行。

值得注意的是作者将这个模型应用到了气胸分类(CXR pneumothorax classification)上面,使用CXR-14数据集。
SSA - tbd
本文利用带有和不带有伪属性注释的两种样本来训练一个预测伪属性的模型,然后使用训练出的模型预测的伪属性作为对伪属性的监督,来训练一个具有最小最坏群损失(worst-group loss)的新鲁棒模型。
先用已有的labelled datasets和unlabelled datasets训练一个模型给unlabelled data赋予pseudo label,用threshold平衡不同类的样本数量,然后再用生成的pseudo label来训练一个模型,用来预测目标label,最小化worst-group loss。
QuestionSection 4引言说给unlabelled data赋予pseudo label,Section 4.3说把pseudo labels给所有的training data,就相当于在这个数据集里把labelled data当成unlabelled,然后再有一个是labelled data?
G-DRO
本文target:
通过DRO() 在训练和测试数据具有不同分布时提高鲁棒准确率。
构造数据集的方式:

上面三个数据集的设计思路是一样的,数据集的group是这样构造的: 95%为bias-aligned, 5%为bias-conflict。通过此数据集研究所得模型的偏好。需要注意的是, 验证集和测试集的比例是均衡的 (50% vs 50%),这能更好地验证模型对于每个group的表现。
作者比较了四种方法:
-
ERM: ,其中为训练集上的经验分布。
-
group DRO: 假设target中的,其中是一个维的单纯形,我们认为中包含的分布由个部分组合而成,所以我们可以得到:
怎么来的?
实际上就是使得各个group的最大化经验损失最小化。
- group adjustment DRO:当训练集上的经验分布与真实分布一致的时候通过G-DRO就能缓解bias-conflict的问题,但是往往存在generalization gap ,所以我们引入一个估计量,用来抵消这个误差。
其中代表模型的拟合能力,代表小的group相较于大的group过拟合的倾向程度。
- importance weighting:用来平衡分布的常用手段。
选择每组训练频率的倒数:。直观上,这试图通过提高少数群体的权重来平衡平均和最差群体的错误。具体地说,从每一组中以等概率抽样来训练加权模型。
- online G-DRO

Pseudo Bias-Balanced Learning for Debiased Chest X-ray Classification
tbd.
Reference
[1] Nam, J., Cha, H., Ahn, S.S., Lee, J., Shin, J.: Learning from failure: De-biasing classifier from biased classifier. Advances in Neural Information Processing Systems 33 (2020)
[2] Lee, J., Kim, E., Lee, J., Lee, J., Choo, J.: Learning debiased representation via disentangled feature augmentation. Advances in Neural Information Processing Systems 34 (2021)
[3] Hong, Y., Yang, E.: Unbiased classification through bias-contrastive and biasbalanced learning. Advances in Neural Information Processing Systems 34 (2021)
[4] Yoonho Lee et al.: Diversify and Disambiguate: Learning From Underspecified Data. arXiv (2022)
[5] Junhyun Nam, Jaehyung Kim, Jaeho Lee, Jinwoo Shin.: Spread Spurious Attribute: Improving Worst-group Accuracy with Spurious Attribute Estimation. ICLR (2022)
[6] Sagawa Shiori, Koh Pang Wei, Hashimoto Tatsunori B., Liang Percy.: Distributionally Robust Neural Networks for Group Shifts: On the Importance of Regularization for Worst-Case Generalization. ICLR (2020)
[7] Luo Luyang, Xu Dunyuan, Chen Hao, Wong Tien-Tsin, Heng Pheng-Ann.: Pseudo Bias-Balanced Learning for Debiased Chest X-ray Classification. MICCAI (2022)
